



As a developer, you may not have spent a lot of time thinking about database connections. A single database connection is not expensive, but as things scale up, problems can arise. So let’s dive into the world of connection pooling, and take a look at how it can help us build more performant applications
A typical way of database connection
Before we get into pooling, let’s quickly review what happens when your application connects to the database to perform a database operation:
- The application uses a database driver to open a connection.
- A network socket is opened to connect the application and the database.
- The user is authenticated(means database user).
- The operation completes and the connection may be closed.
As we can see, the opening and closing of the connection and the network socket is a several step process that requires computing resources. However, not closing the connection and keeping it open all time also consumes resources.
Why pool database connections?
For a simple application typical way of connecting databases may suffice but when your application gets some amount of users, a simple database operation might take a few seconds. Also, the constant opening and closing of connections for each database operation will consume too many resources.
Often, it makes sense to find a way of keeping connections open and passing them from operation to operation as they’re needed, rather than opening and closing a brand new connection for each operation.
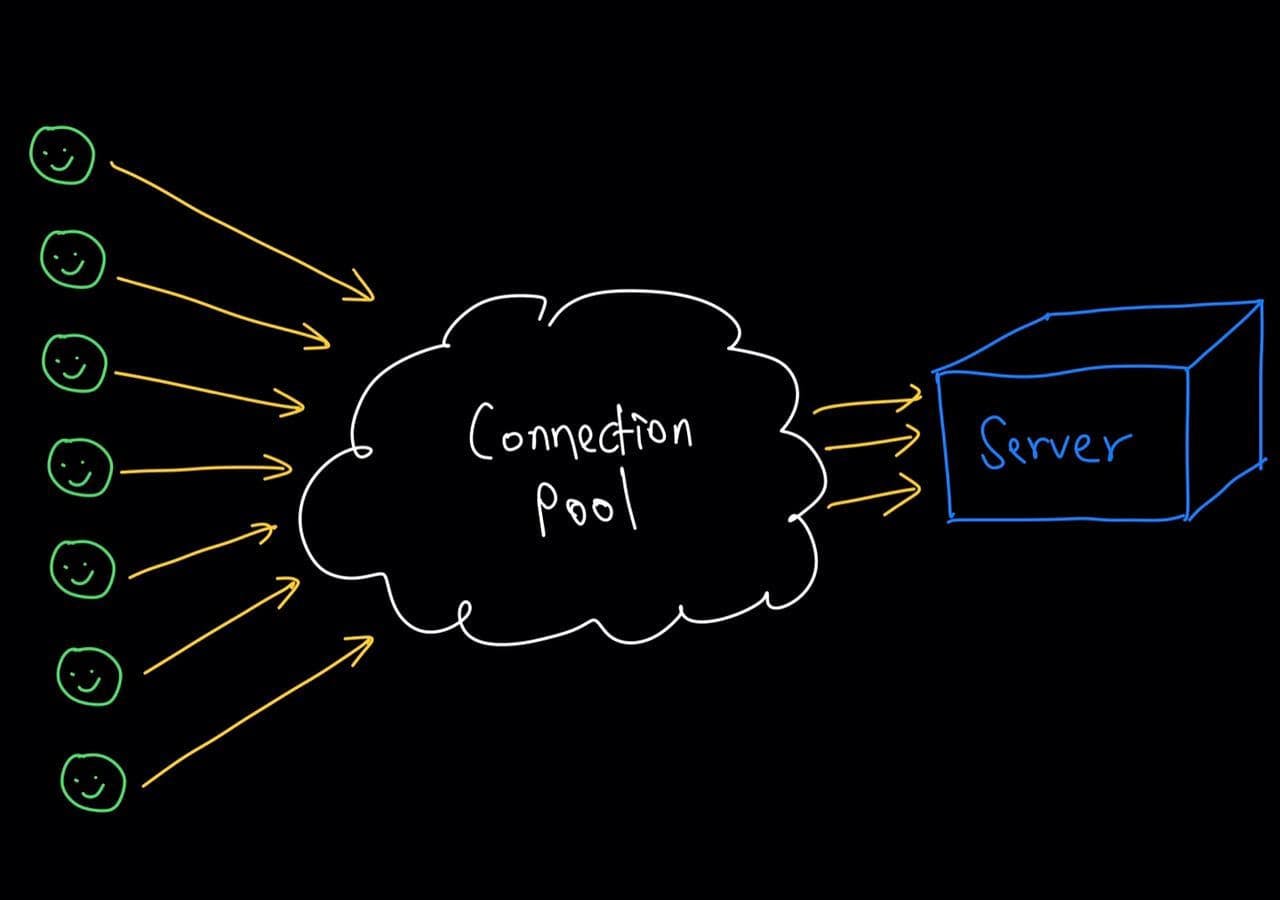
What is database connection pooling?
Database connection pooling is a way to reduce the cost of opening and closing connections by maintaining a “pool” of open connections that can be passed from database operation to database operation as needed.
How to create and configure connection pools?
For an example, I'll take PostgreSQL and sequelize ORM to demonstrate.
But almost all kinds of database or ORM supports connection pooling.
below code snippet contains some defaults values
pool: {
max: 5,
min: 0,
acquire: 30000,
idle: 10000,
}
max ->maximum number of clients pool can extend concurrently.min ->minimum number of clients pool can extend concurrently.acquire ->The maximum time (in milliseconds) that pool will try to get connection before throwing error.idle ->The maximum time (in milliseconds) that a connection can be idle or
wait for any database operation before being released.
These are the minimal configurations needed to get started quickly.
You always look back and add more configuration as per your requirement.
Thank You for reading.
Feel free to share your thoughts on the comments section.
Follow me for more such content like this.